Today I patched a monster.
That monster is a piece of code that many of you probably rely upon, either directly or indirectly.
I’m talking about the garbage collector in the .NET Core runtime from Microsoft. It’s a critical piece of code that I never intended to touch. The reason I ended up there was because I was on the hunt for good test data for our analysis tools as I explored an interesting approach to write more efficient parsers. This story isn’t so much about the bug I found, which was trivial to fix. Instead I want to share an example on how we can simplify complex problems by rethinking them.
The Need for Monsters
The Apollo program is often claimed to be humanities greatest engineering achievement. To me, it’s clear that anyone who makes that claim has never looked at a C++ compiler. The complexity of a C++ compiler makes landing on the moon look easy. And I’m only half-joking since I spent the past weeks implementing a C++ parser.
Now, you probably wonder, why on earth would someone do that (parse C++, not land on the moon)? Don’t we already have high-quality C++ parsers? Of course we do. The thing is I needed our parser to be orders of magnitude faster so I had to take on the challenge. Let me explain why.
I develop tools for software analysis. Our analyses are a bit different since we focus on the evolution of a codebase rather than a static snapshot of the code. For example, given a large codebase with hundreds of developers, how do we prioritize improvements? Which technical debt actually matters? Software evolution provides a critical part of the answer to questions like that.
The concept of Hotspots is a central part of our analyses. A Hotspot is complicated code that you need to work with often. That is, Hotspots are based on how you actually work with the code and not just its static properties.
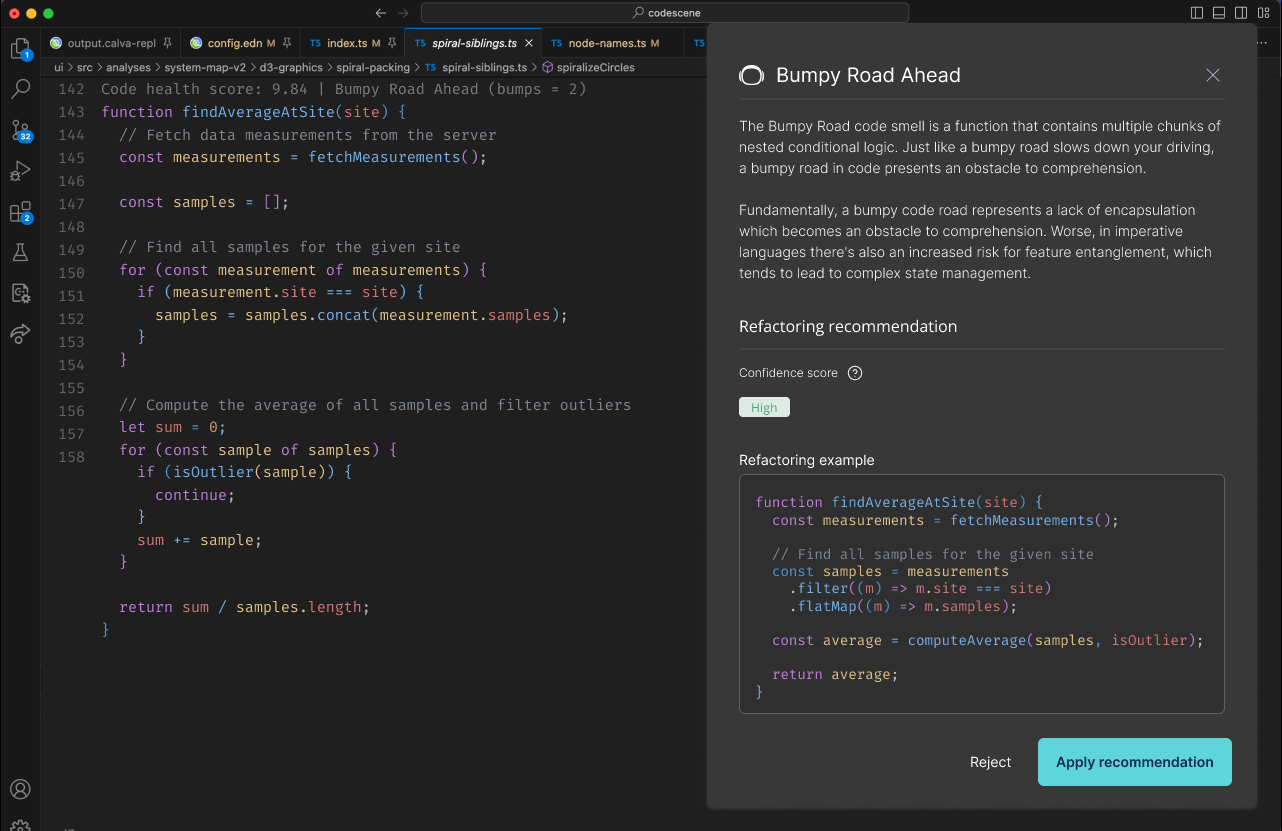
For a long time we presented Hotspots on a file level. In most cases those Hotspots give you information you can act upon. However, sometimes you come across a Hotspot file with several thousand lines of code. And to point someone to, let’s say, a file with 6.000 Lines of Code and say “hey, here’s your problem - just refactor this module and you’re fine” isn’t that helpful. Hence we started to work on our X-Ray feature that I introduced in the Software (r)Evolution series.

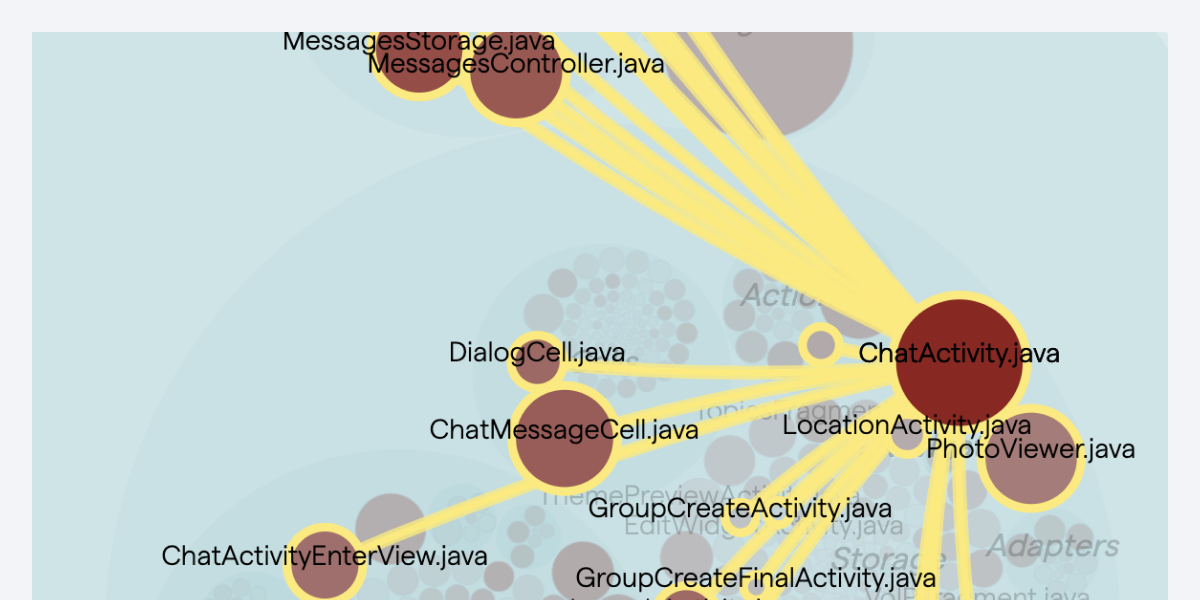
A Hotspot example on CoreCLR. Hotspots identifies complicated code that we also have to work with often.
X-Ray lets you identify Hotspots inside a file with the resolution of function/method level. To pull that of we need to analyze the source code, which explains my interest in parsers. Let’s meet some of the challenges here.
The challenges of complex languages
Programming languages differ a lot in syntax. For example, the Lisp language family is trivial to parse since Lisp has a minimalistic and uniform syntax. On the other end of the spectrum you’ll find C++. C++ is notoriously hard and expensive to parse. That’s particularly true in modern C++ that makes heavy use of template meta-programming.
I’ve been torturing C++ compilers for a living. I’ve seen compilation times go through the roof to the point where they become a serious productivity bottleneck. The performance impact hits our tools harder because we have to make lots of passes through a file. The reason is because we analyze the evolution of code, which means we need to parse each historic revision of a file. Large hotspots may have hundreds of revisions so each performance hit adds up quick.
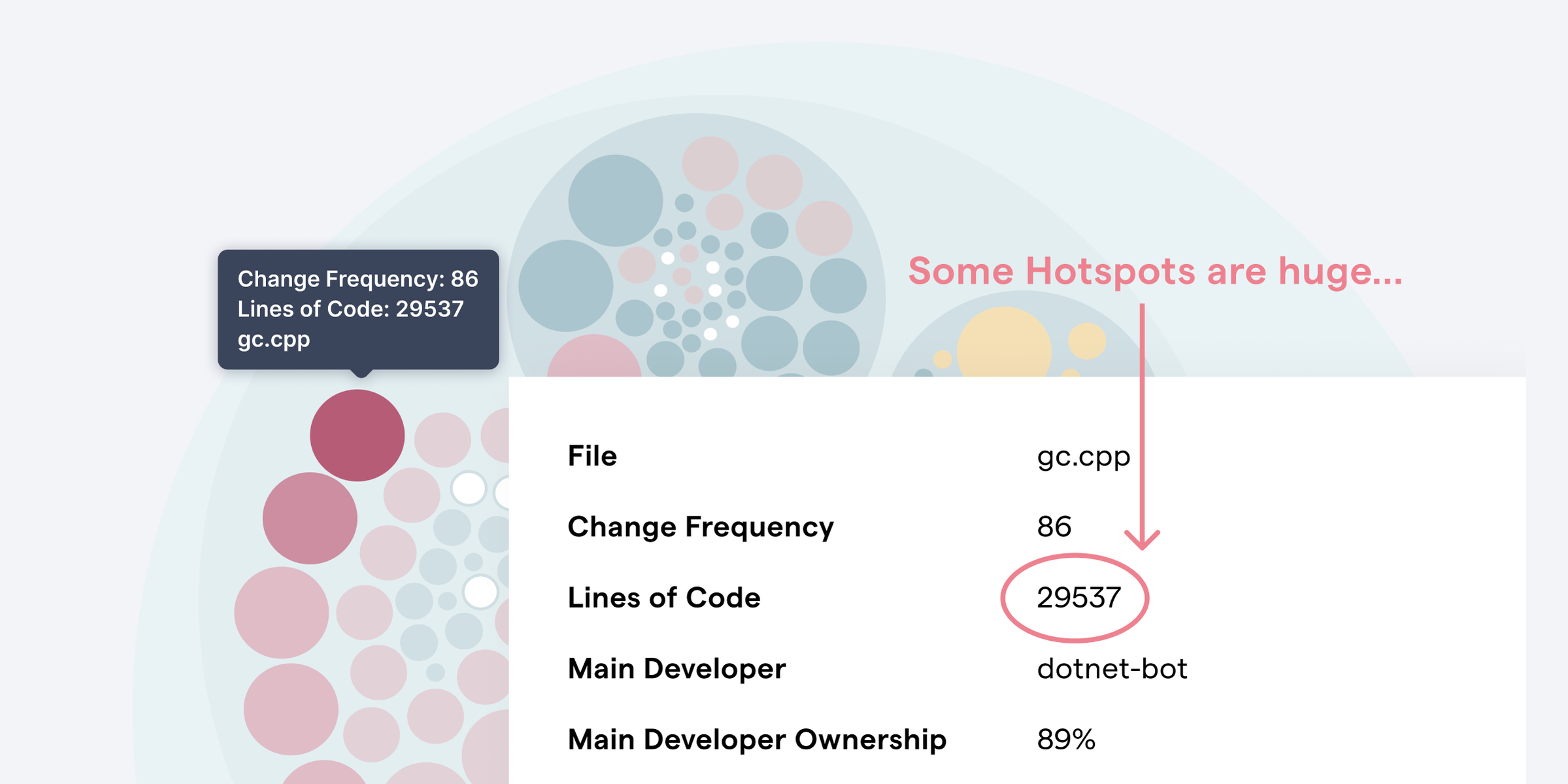
Our first approach to parsing C++ was to use a complete language grammar for C++ 14. I do write unit tests for different corner cases, but prefer to rely on real-world production data for most tests. I’ve found that approach gives me the most return on the time I invest in tests. Since C++ has so many styles and flavors I tested on lots of different open source projects. I also managed to find an excellent measurement stick for performance: gc.cpp from the .NET Core runtime.
gc.cpp is a C++ file with around 37.000 (!) lines of code. In fact it’s so big that GitHub refuses to render the code:
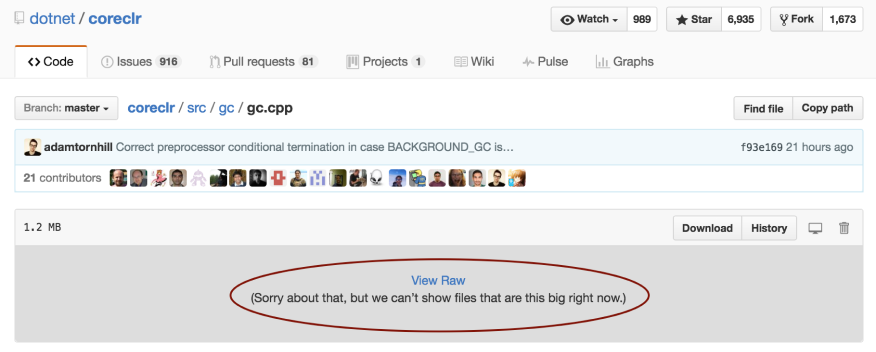
The file gc.cpp is so massive that GitHub cannot render it with syntax highlighting.
Now, 37.000 lines of code would be scary in any language. In C++, with its low-level abstractions and manual memory management it becomes a true monster. Now, I do encourage you to take a quick look at the code. I’ll wait here, so please go ahead and have a look.
gc.cpp isn’t particularly object oriented. In this case, C++ is used more as what Bjarne Stroustrup labels a “better C” (and yes, some of us would like to add: “for some definition of better") with a slightly stronger type system and basic classes. gc.cpp is critical code both in terms of performance and correctness; An error here will impact millions of users and software systems. It’s the kind of code that’s both really impressive and downright scary at the same time.
Our first attempt at a full-blown C++ parser failed miserably here. First of all gc.cpp took forever to parse (forever in this case means more than a minute). Since we had ~80 revisions of gc.cpp to parse this became quite impractical. In addition, the real parser didn’t play well with macros and other preprocessor directives. Adding that support was just not an option since we’d end up with even worse performance. We had to do better, which lead me to investigate a novel strategy based on something called micro-grammars. Let’s see what a micro-grammar is.
Micro-grammars: When less is more
I often get asked by different companies how they can simplify their code. There are of course lots of different strategies, but the most important one starts at the other end. It starts with the problem. I’ve found that simplifying the problem we try to solve has a much higher pay-off than focusing on the solution. I applied that lesson myself as I tried to improve our C++ parser. The approach is based on a concept called micro-grammars. Let me give you an example.
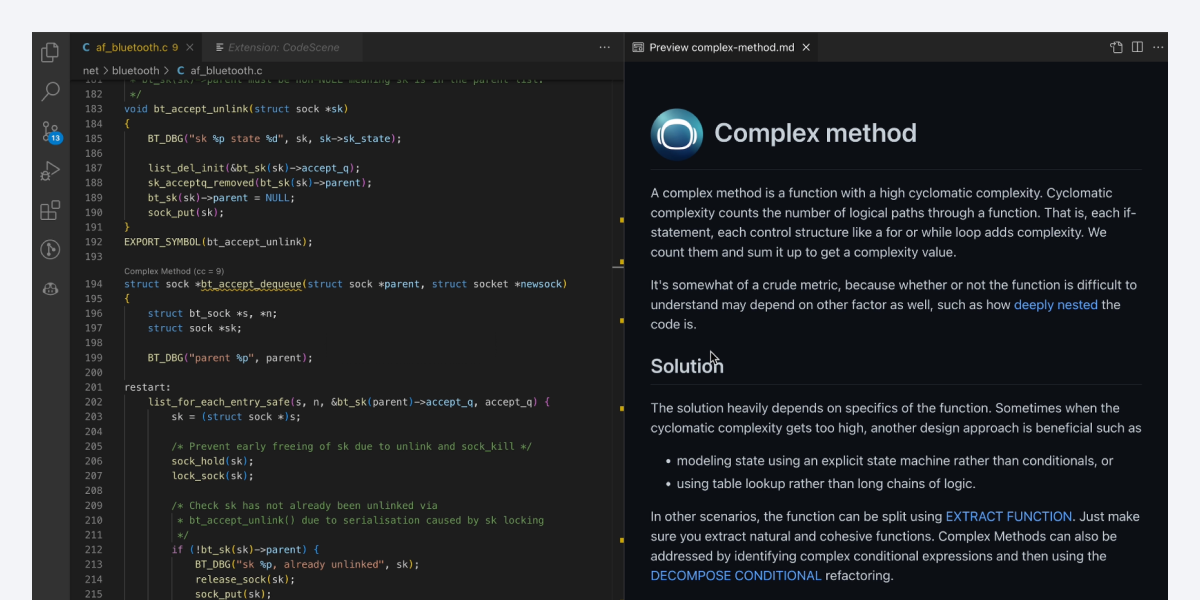
If we want to get an approximation of how complex a piece of code is, we could calculate its Cyclomatic Complexity. That means we need to count the number of branches and loops in a function. With micro-grammars we simplify the problem by realizing that most code isn’t important to us. Let’s say we attempt to parse an if-statement. The detailed conditional statement doesn’t carry any additional information so we’re free to ignore most details. With a micro-grammar we embrace that fact and only parse the general structure. That is, the conditional itself and any logical boolean expressions while discarding the details.
When suitable, a micro-grammar approach massively simplifies parsing. Our complete C++ 14 grammar consisted of more than 2.000 lines of tricky rules. As I re-wrote it to a micro-grammar approach I reduced the rule set to 90 lines of code. And those 90 lines include both the lexer and parser rules. This reduction in both size and complexity makes wonders for our abilities to reason about code. 90 lines is something that we can build a mental model of and hence reason about. That was a big win as I moved on to optimize the grammar rules - it’s hard to optimize code we cannot reason about.
This reduction in the cognitive effort needed to understand the code is a big win. But the critical win was with respect to run-time performance. Using the micro-grammar approach we’re able to parse gc.cpp in ~400 milliseconds. That’s orders of magnitude faster. More important, it’s fast enough for our tools to provide a good user experience. And please note that the implementation is in Clojure, which isn’t exactly known for its blazing speed. It’s interesting however that we can get this significant performance increase by rethinking the problem rather than traveling down the abstraction ladder and re-implement the code in a low-level language.
Even more surprising was that our micro-grammar was good enough to detect a bug in gc.cpp that real parsers miss. Let me explain why.
Catching a bug in gc.cpp
So far I’ve praised the micro-grammar approach. However, I want to point-out that writing a micro-grammar isn’t necessarily easy. The trick, particular with respect to performance, is to minimize look ahead. To a micro parser this means we need to keep the grammar general enough to be agnostic about large parts of the language while at the same time be very specific when it matters. It’s a trade-off and also the reason why micro parsers are hard work.
Once such trade-off was C++’s conditional compilation. We cannot just strip away conditional compilation statements since it would lead to invalid coding constructs like unbalanced curly braces in some cases. So we had to be aware of conditionals and this is when we found the bug in gc.cpp.
After I had celebrated the performance victory I realized that I got a warning from the parser. My error handling strategy is to report parse failures and then try to re-synchronize on the next recognized parse token. The warning I got complained about an extraneous closing curly brace, }. Now, I suspected a glitch in my parse rules and did spend some time debugging it before I looked at the test code. Here’s what I finally found:

A walk-through of the bug that the micro-grammar found.
As you see in the code above, the moment someone undefines BACKGROUND_GC, the code won’t compile anymore.
I try to be a good citizen, so once I found this bug I patched the error and submitted a pull request to the CoreCLR project. My patch was trivial and not that interesting in itself. Whats interesting though is that the bug, as trivial as it is, has hidden undetected for a long time. And that in a critical, well-tested and peer reviewed codebase. The first take away is that software is just incredibly hard to get right. It’s also fascinating that there are cases where a micro-grammar catches problems a full scale compiler might miss (pre-processing isn’t really part of a C++ compiler). The second take away relates to the micro-grammar itself. By re-thinking the problem we managed to significantly reduce the complexity of our code and won big on run-time performance too.
Now, before I leave you, what about the X-Ray results on gc.cpp? Well, with our micro-grammar we’re able to analyze the whole evolution of the file and answer that question. Its top hotspot, on a function level, is the function gc_heap::grow_brick_card_tables. It’s a function with 329 lines of code. The data indicates that simplifications to that code is likely to make future maintenance cheaper since that function is the part where most of the development effort in gc.cpp has been over the past year. In addition, we can see that the hotspot gc_heap::grow_brick_card_tables becomes more complicated over time:

A complexity trend on function level reveals that the Hotspot inside gc.cpp keeps accumulating complexity.
Try the analysis on your own code
We provide these analyses both on-prem and as a service, so sign-up and explore the Hotspots in your own codebase. CodeScene.io is free for open source projects. And should there be any bugs in our C++ X-Ray feature, you know I’m to blame.