Tightly coupled microservices are a cardinal sin.
The moment we introduce strong coupling between our services, we lose the potential advantages of a microservice architecture:
- We can no longer deploy services independently,
- Our teams will spend more time in sync meetings than in the code, and
- The system becomes incredibly hard to maintain. It’s expensive.
At the same time, it’s harder to reason about dependencies in a distributed microservice system than a traditional monolith. Part of the reason is that static dependency analyzers tend to break down: in a microservice architecture, there aren’t any explicit dependencies in the code, only indirect dependencies via API calls and messages exchanged over a network.
This article addresses the challenge by introducing the concept of a Change Coupling analysis. Change Coupling is a behavioral code analysis technique that uncovers logical dependencies across services and team boundaries. Let’s see it in action.
Prioritize Dependencies that cross Team Boundaries
Tighly coupled services are problematic in general, but there are different circles in any dependency hell. In particular, dependencies between services that cross team boundaries are expensive and immediately creates delivery bottlenecks. Change coupling lets you visualize those dependencies:
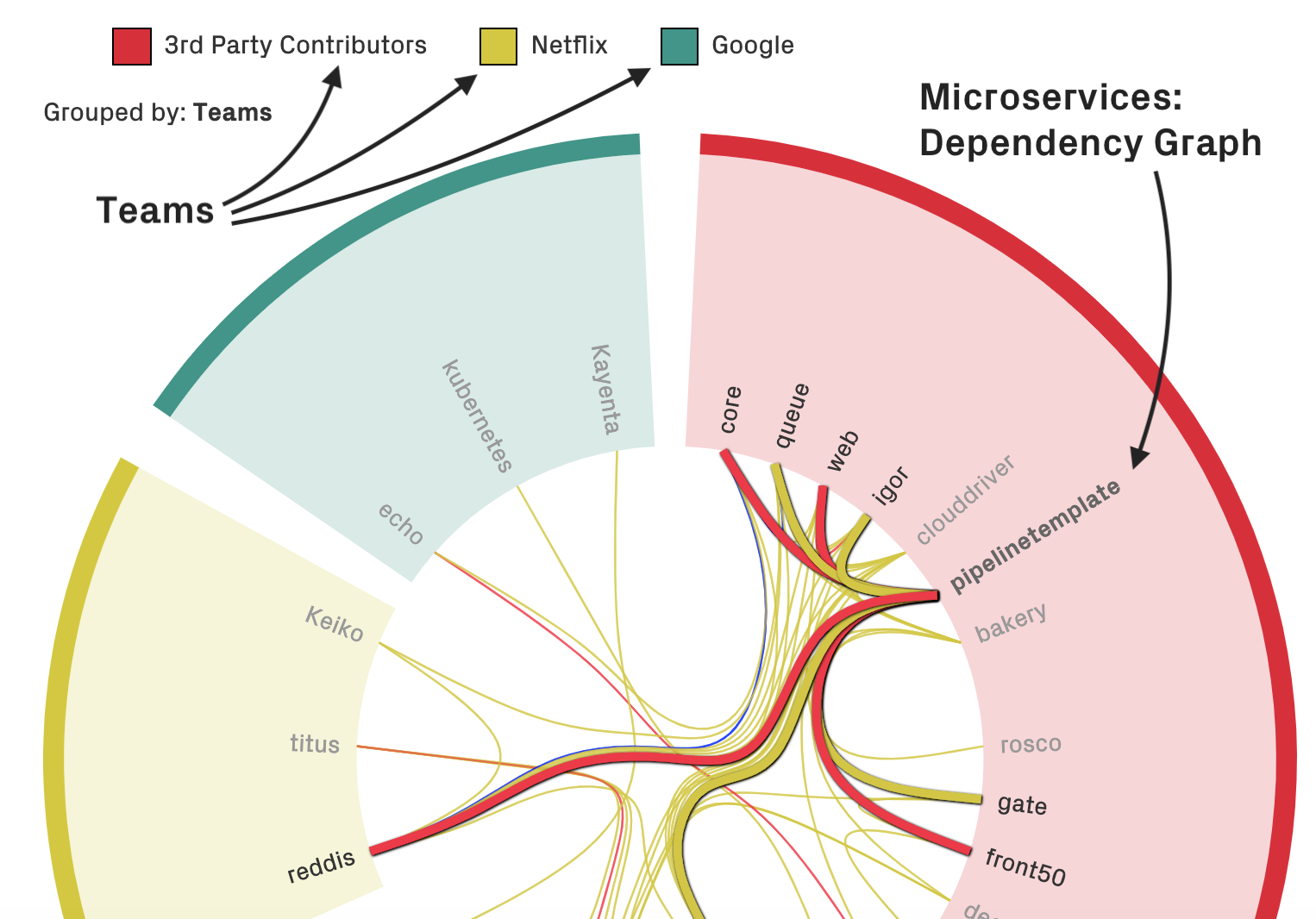 Visualizing a dependency graph between microservices within the context of the development teams.
Visualizing a dependency graph between microservices within the context of the development teams.
The preceeding figure shows the dependencies between different microservices. The services are grouped by their primary team. That way, we can quickly identify dependencies that cross team boundaries. Let’s dive into change coupling to understand how we get that data.
Introducing Change Coupling: uncover logical dependencies
Change Coupling means that two or more modules tend to be changed together, often by having some logical dependency on each other. Consider the following scenario:
 Change Coupling means that two (or more) modules repeatedly change together over time.
Change Coupling means that two (or more) modules repeatedly change together over time.
In this picture, we see that the first time we make a change to our system, we’re modifying Subscription and Sign-Up services as part of the same change set. In the second change, we modify another service. Finally in the third change we’re back to modifying the Subscription and Sign-Up services together.
If this is a trend that continues, then we know that the evolution of the Subscription and Sign-Up services are tied to each other: changes to either one of them are coupled in time to the other service. We have discovered a change coupling relationship.
Automated Change Coupling Discovery
Now, where do we get this data? Well, change coupling is invisible in the code itself. Instead, we need to combine version-control data from Git with issue data from a product management tool (e.g. Jira, Trello, Azure DevOps). That way, we can detect when a code change in a specific service references an issue that also involves modification of another service. Here’s how it works: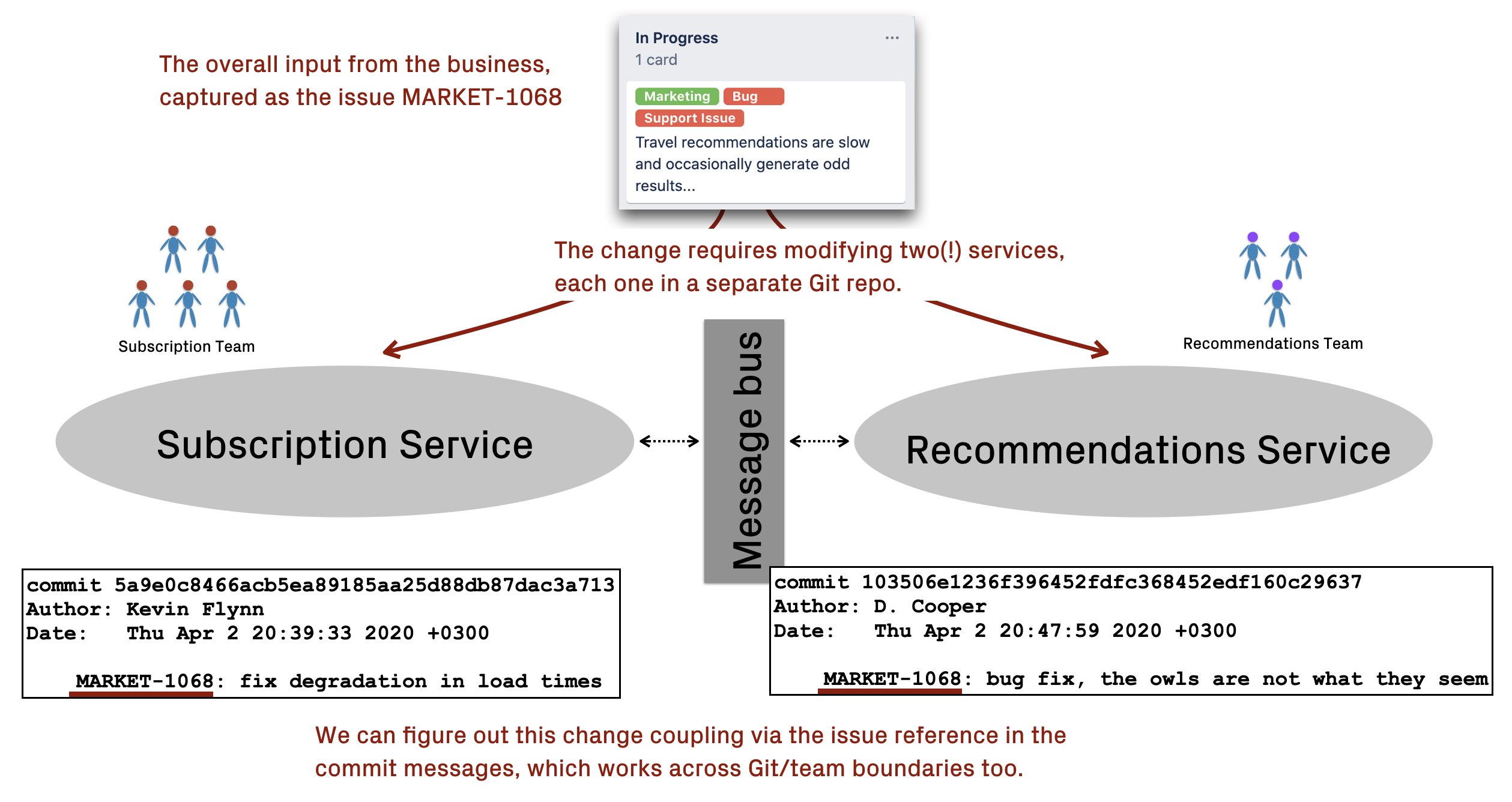 Analyse Change Coupling in a microservice architecture via issue reference in the commit messages.
Analyse Change Coupling in a microservice architecture via issue reference in the commit messages.
As you see, the only prerequisite is that there exists a way of linking the commits to Jira data. Each commit could include the issue reference in the commit message as shown in the preceding figure, or the Git branches could reference the issue in their names (e.g. rd-123-publish-recommendations). A tool like CodeScene can then automate the data mining and analysis, and the information you get is well worth the additional bookkeeping that of course can be automated too.
Adding the Team Dimension
As discussed earlier, a microservice change coupling dependency is more problematic if it spans multiple development teams. To discover those dependencies, we added a team dimension to the change coupling graph as shown earlier. That data came from one of the most under-utilized data sources in the software industry: version-control.
By mining version-control data, we can measure where in the code each author works. And those individual authors can be aggregated into teams. That way, we can visualize the operational boundaries of each team (see Software Design X-Rays for the full treatment).
Almost as a bonus, we can use the same data to reverse engineer a microservices ownership map based on actual code contributions:
 Visualize the primary team behind each microservice based on code contributions.
Visualize the primary team behind each microservice based on code contributions.
This is something we can use to reason about the cognitive load of each team (see the Team Topologies book for an in-depth discussion).
Summary: Microservices can quickly become Macro Problems
Microservices is a high-discipline architecture where loose dependencies are key. Failing that, we’ll face a situation where it gets hard for a team to operate in an autonomous way. Just like we expect alerts from our production environment, we really should monitor the key architectural properties so that we can act upon dependencies early.
The beauty of change coupling is that it also works across Git repositories. All you need is to make sure your commits are linked to a high-level story, and I hope this article has inspired you to explore the concept on your own code. If you want to give it a go, then CodeScene is available for a free trial.

.png)