We've been working on better refactoring tools for teams that want to improve their code, and we're happy to present our new Refactoring Recommendations feature - a refactoring catalog created from the improvements made to your own team's code.
First, let's set the stage by discussing why refactoring is important, hard, and in need of tool support.
Refactoring
"Refactoring is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior."
– Martin Fowler
Primarily we refactor to manage complexity. Without an approach to reducing complexity, we can only watch it grow over time.
Refactoring is difficult work because it's in tension with other goals, like delivering features or fixing bugs, and the benefits are long term and hard to quantify. If we're refactoring in a code base that has low test coverage, it can also be risky to refactor the code without altering the behavior of the software.
Since the intended goal of a refactoring is subjective – make the code easier to understand and work with – it will exist in a social context as well. If we're not in agreement on what's understandable, either one of us using a lot of effort to change the system will be a net loss.
As toolmakers confronted with something difficult, our solution is of course to build a tool. But first, let's have a look at the existing tools that help developers refactor.
Existing tools
- Editor tools
Let's lump together editor integrated refactoring suggestions and semantic linters into the category of editor tools.
These tools help with the mechanical execution of refactoring, and also in discovering some of the simpler code smells that you might run into, like code duplication. They are easy to use and a great help in performing the refactoring you've decided on, but they lack the context required to help you with both when, where and into what you should refactor code.
A huge plus with editor tools, from the point of view of someone wanting to change the way a software team works with code, is that they are very easy to pick up and showcase to developers, and many already use them.
- Refactoring books
Another way to help foster a culture of refactoring in your team is to learn about the principles of refactoring, and there are plenty of good books written about that. We've been inspired by both "Working effectively with legacy code" by Michael Feathers, and Martin Fowlers "Refactoring".
The whole team having a deep understanding of an area of software development is of course desirable, and I would encourage everyone to read these books. If you're looking to improve your team's software engineering capabilities, you could do far worse than reading these books in a book club at work.
The books are complemented by various iterations of a refactoring catalog, which are distilled recipes for refactoring. These can really aid with pattern matching and quickly looking up a code smell and patterns that you can use to rectify them.
There are some drawbacks to the book and catalog approach. First, reading books and discussing things takes a lot of effort, and you'll need to compete with every other area of software engineering that could be improved by reading a book and talking about it with your team.
Second, knowing patterns and how to apply them don't necessarily help you with when to apply them, or which ones to pick – especially as a team. What if you like a couple of different solutions for a common problem?
Third are the necessarily generic examples. When you're writing a book, you'll need to compromise on the specificity of your examples to apply to a general reader. That means one language and one domain, which is unlikely to be our domain and our language.
Overall they are a great read and I would recommend it, but it's by no means a quick fix to getting more refactoring done in your team.
- Your own refactoring catalog
In general the issue with the aforementioned tools is that they lack the necessary context to help your team refactor effectively. It's hard to know when, where and into what pattern we should refactor.
This is where we saw an opportunity inside CodeScene. We know some interesting context around refactoring – CodeScene's code health algorithms find complexity in source code, and is able to score each change to source code in terms of the change to code health.
Because we have that data we can find both degradations and improvements in code health, and that's the basis of how we can start curating refactorings from your own code base.
The idea is that we provide you with your very own refactoring catalog, and when a piece of code is in need of refactoring, you'll be presented with a recommendation that's:
- in your domain
- done by your team
- relevant to the flavor of complexity you are dealing with.
How does it work?
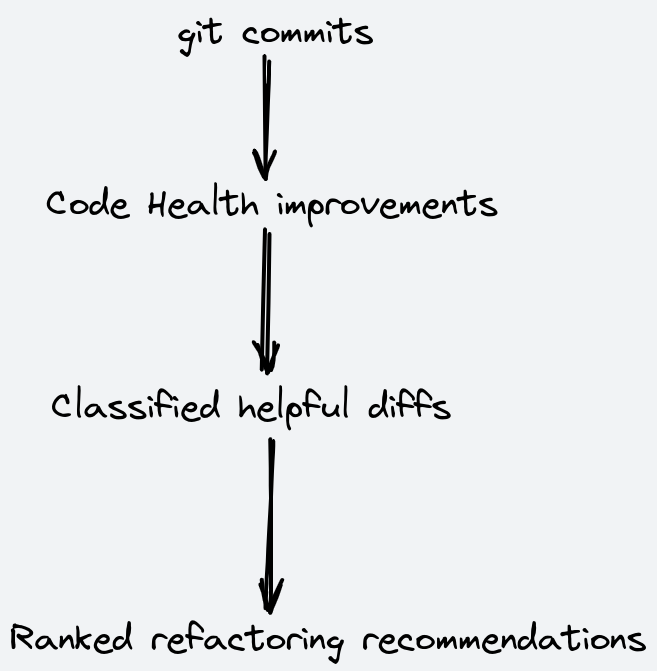
We have a couple of interesting data sets. First of all we have the source code from the software project (or multiple projects). Any time someone makes a new commit to the source code, CodeScene's code health algorithms decide if it's an improvement or a degradation of health. We then use the degree of improvement as the first label of our data set.
In the second stage of processing every diff that CodeScene has labelled as an improvement to the code health is collected, and then fed into a machine learning model that is trained to classify improvements as either helpful or not helpful.
We do both implicit and explicit labeling of your data. There's a simple voting option (thumbs up/down) that is available where the diffs are shown, and these votes are heavily weighted in our algorithms so that we can bubble up the things you find the most helpful to the top. We are iterating on a couple of implicit labeling schemes where we try to figure out how helpful a refactoring recommendation is by the actual usage in our system.
This data is eventually fed back into our ML models to refine their classification.
We're ranking the refactoring recommendations by a couple of factors, including our social and architectural distance calculations.
The highest ranked refactoring recommendation for you will be:
- classified as helpful by our ML model;
- large code health improvement;
- close to you socially (by a team mate or close collaborator);
- architecturally close (roughly by file distance in the folder hierarchy).
By adding these factors to our ranking we try to make the recommendations relevant both by domain and socially.
Showcase
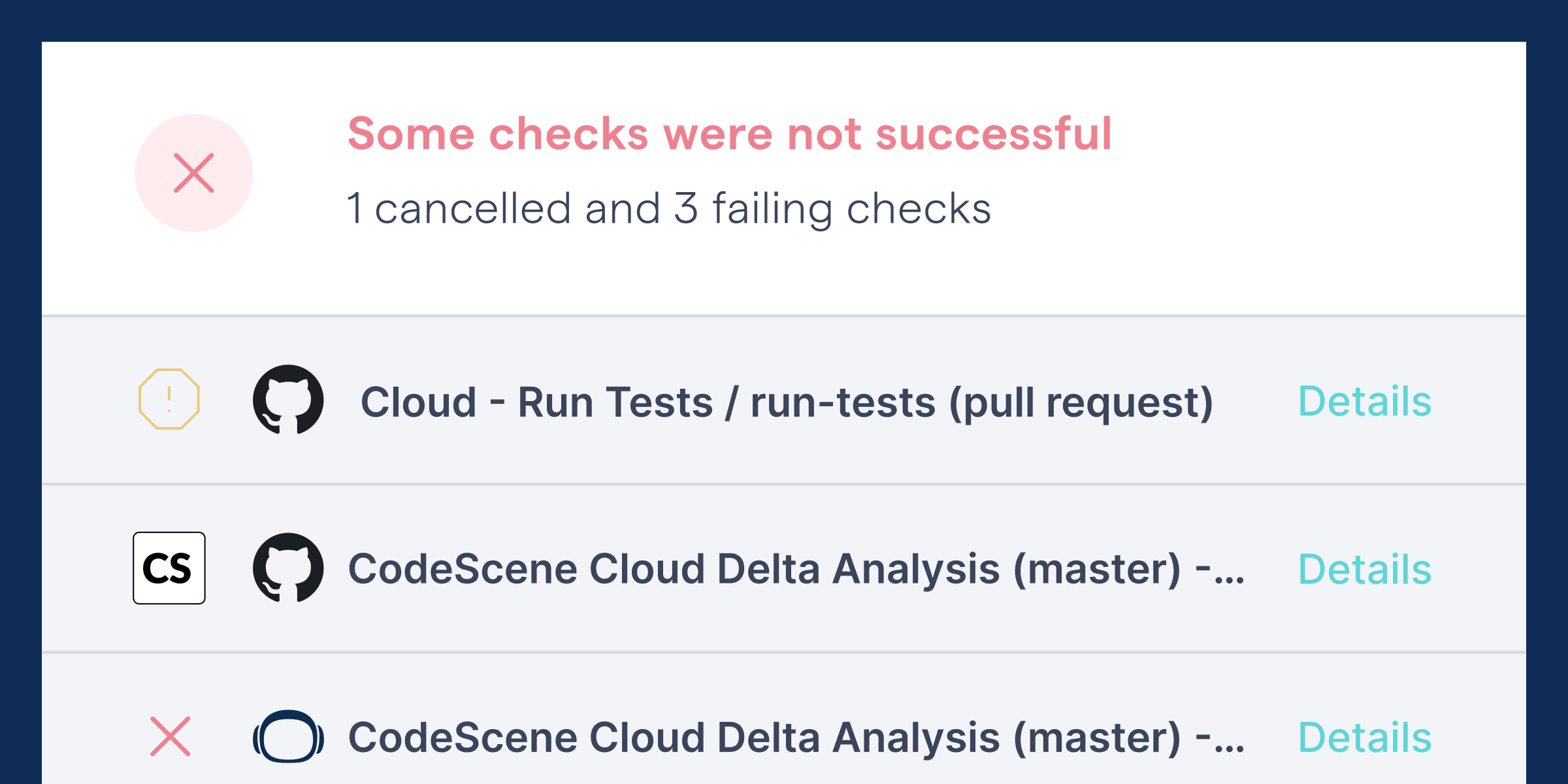
We'll start out at the pull request check, which is where the developer encounters CodeScene. If you've touched code that is in poor code health, you will be presented with a quality gate in the form of failing checks:
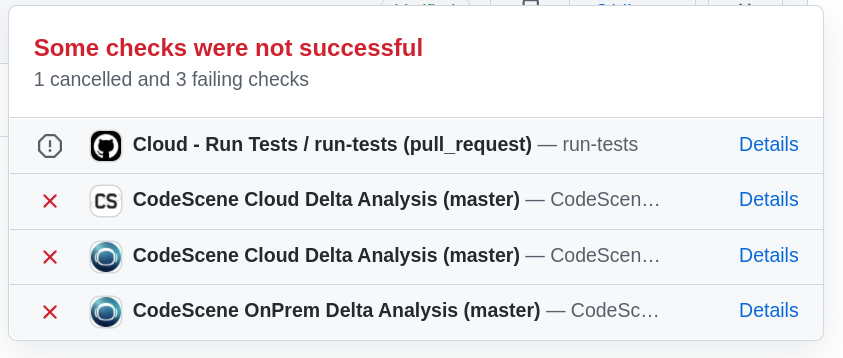
Fig. 1 - CodeScene's pull request integration.
This gives us a precise time and place to consider refactoring. CodeScene will pair up the code health issue it found with recommended refactorings from your own domain.
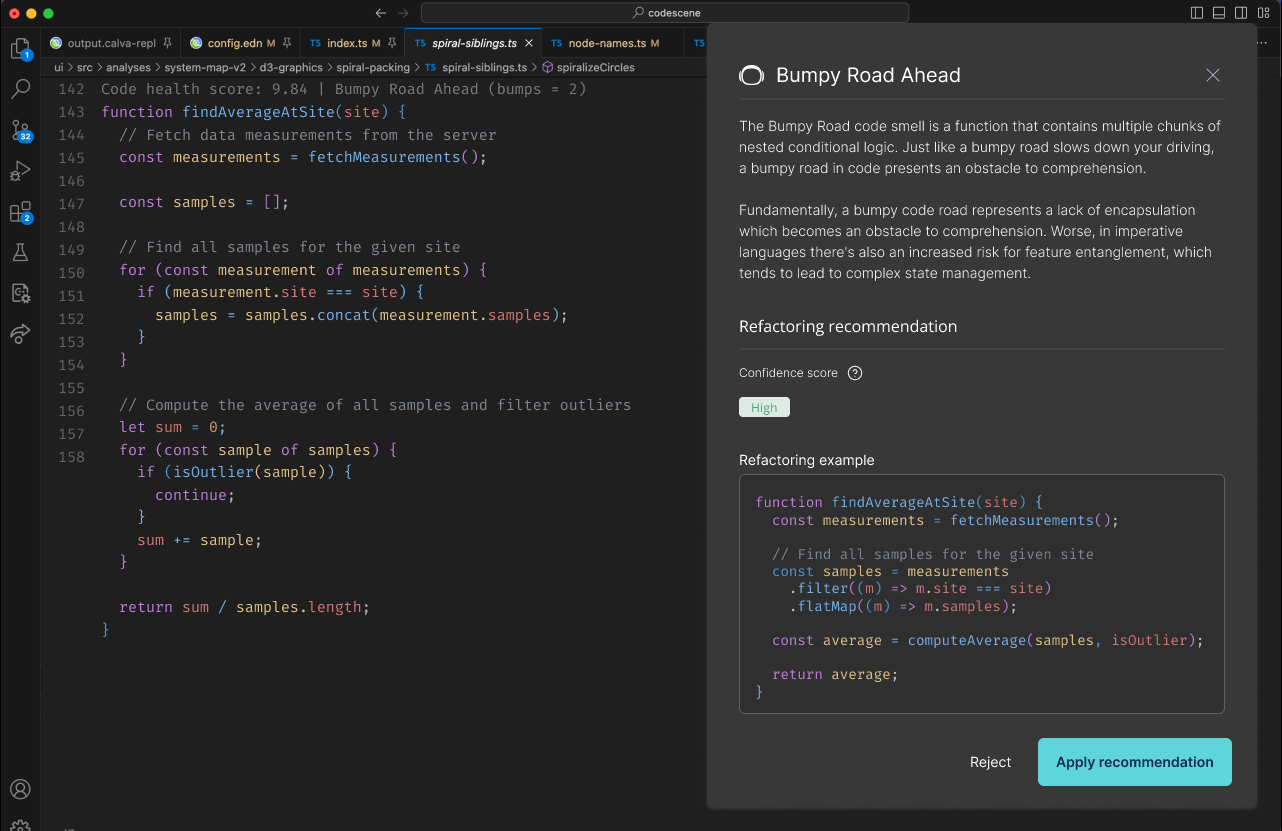
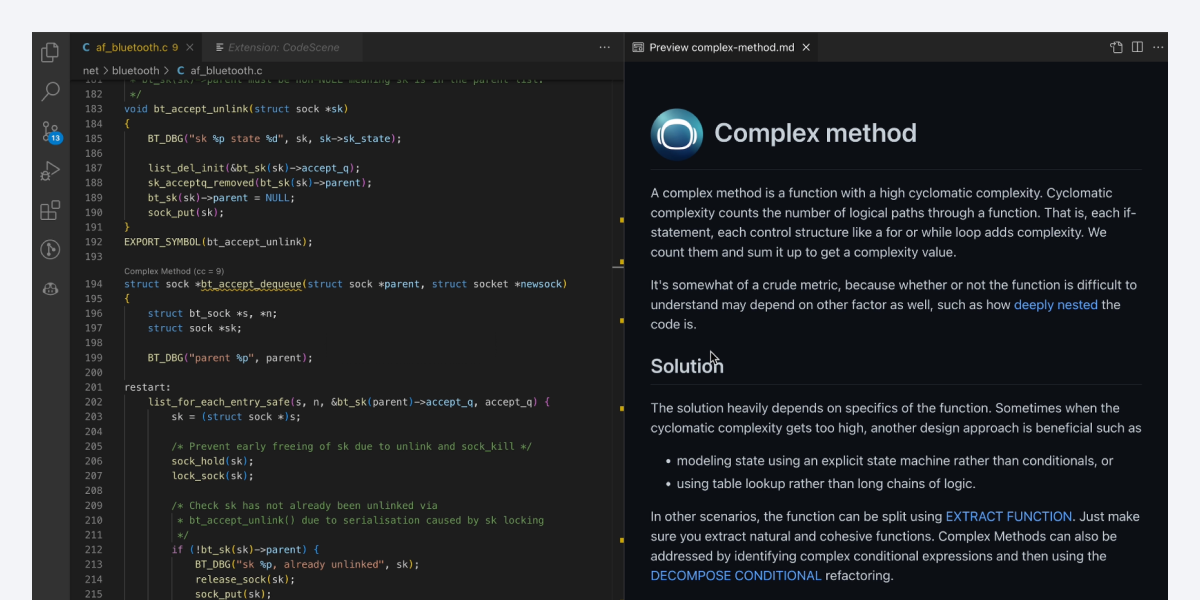
Here's a nice example from the open source project SerenityOS, which illustrates the anatomy of one of our recommendations, with the commit message, the diff and the code health issue that it solves:
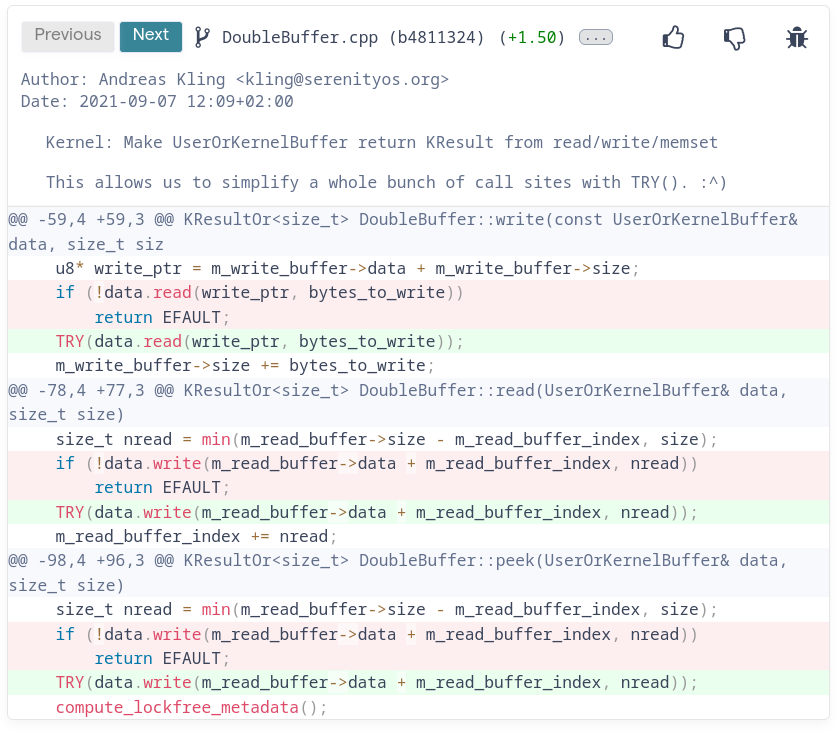
Fig. 2 - A sample refactoring recipe.
Over time CodeScene's algorithms will accumulate a refactoring catalog tailored to your domain, with refactorings performed by your team. All you need to do is activate the Pull request integration and resolve the issues that CodeScene points out.
Fig. 3 - A personalized refactoring catalog book.
Conclusion
We are awaiting our customer feedback on this feature now, because as with all machine learning based approaches the data will is the largest determining factor in how well the feature works.
From our experience in our own code base, there have now accumulated quite a few interesting refactorings, and we are considering how to enhance this functionality further. What's already on the roadmap is bringing forth the refactorings into the Pull request integration in an even more prominent way. Other interesting areas to explore are to build on the social aspect of refactoring even more, by highlighting each others improvements somehow.
Keep on reading! Find out what my colleague Joseph has to say about code complexity.