Everyone in the software industry "knows" that code quality is important, yet we never had any data to prove it. Consequently, the importance of a healthy codebase is largely undervalued at the business level.
We set out to remove the quotation marks so that "knows" becomes knows. We recently published new research that for the first time quantifies the business benefit of high-quality code. Here are the key takeaways:
- Efficient software development is a competitive advantage, enabling companies to maintain a short time-to-market with a mature product experience.
- Research shows that 23-42% of developer’s time is wasted due to technical debt and bad code.
- Code quality is not visible to non-tech stakeholders and possible gains in code quality are hard to translate into business value.
- High quality code has 15 times fewer bugs, twice the development speed, and 9 times lower uncertainty in completion time.
- The findings are from statistically significant and peer reviewed research on 39 commercial codebases from various industries, domains, and programming languages (Python, C++, JavaScript, C#, Java, Go, etc.).
Yes, that's right: high-quality code has 15 times fewer bugs, twice the development speed, and 9 times lower uncertainty in completion time. Let's dig into the findings.
Background: The tragedy of code quality
One of the great tragedies in software development is that code quality lacks visibility. The tragedy is that it becomes far too easy to trade apparent short-term wins -- like new features -- for the long-term maintainability of a codebase. Adding to that challenge, our industry also faces a global shortage of software developers; demand substantially outweighs supply. In my native Sweden alone, we estimate a shortage of 70 000 software developers over the next 3 years.
Given this lack of future recruits, isn't it fascinating that our industry wastes up to 42% of developer's time on technical
debt, including poor quality code? It's simply not sustainable, so why is this waste not only tolerated but allowed to continue?
As a programmer and startup founder, I've spent plenty of time in both code and business settings. In my experience, the costs of poor code quality are well understood by senior engineers. However, to a non-technical stakeholder, code quality remains a vague and abstract concept. This makes it hard for engineering to communicate the trade-offs and need for improvements. Many developers end up having to take on more technical debt as the short-term business goals tend to win over long-term maintainability.
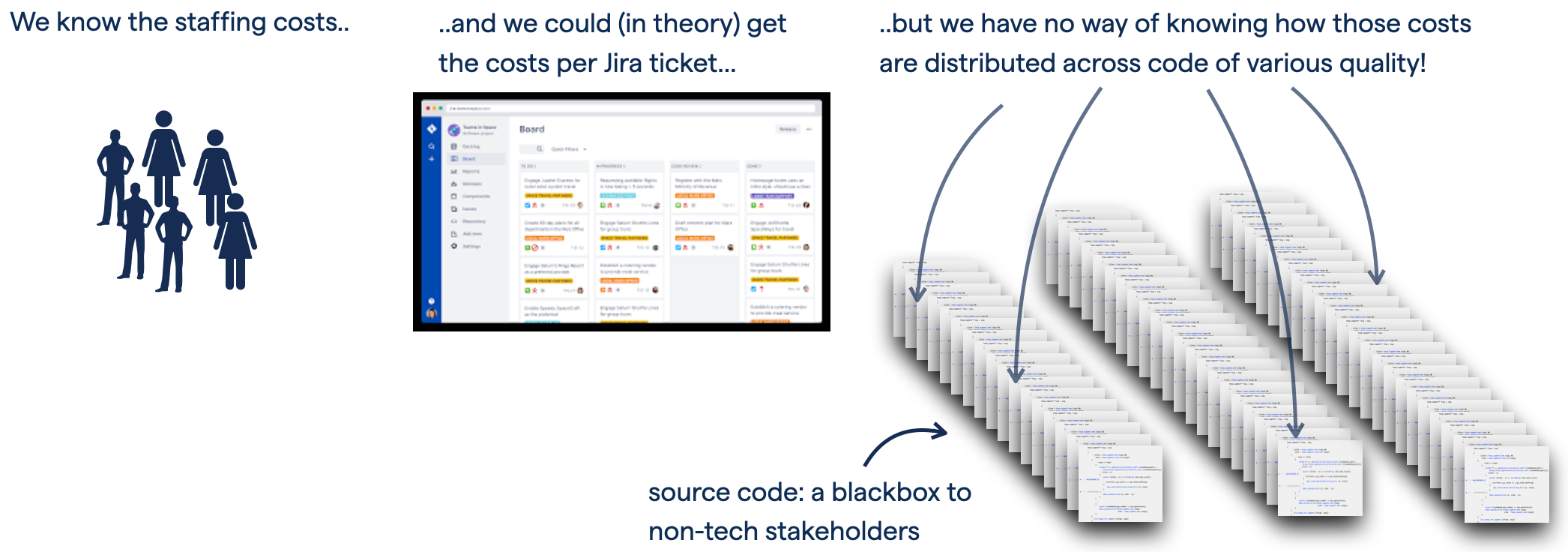
The efficiency loss from low code quality hasn’t been possible to assess at code level before, nor is source code quality well understood. The result is a communication chasm between developers and the business side. This study aims to bridge that gap.
At some point the scale tips and the business starts to suffer the consequences of poor code. Progress grinds to a halt as new features are outweighed by a growing mountain of bug fixes, rework, and demoralisation. If we ever want to break this cycle, then we need to elevate code quality to the business level. This research initiative was launched with that aim.
Hard facts: data on the business impact of code quality
The findings below come from our research paper "Code Red: The Business Impact of Code Quality", which is peer reviewed and accepted for the International Conference on Technical Debt 2022. You find the full paper with all details here, as well as an accompanying whitepaper that's more accessible to wider audience.
The data collection and measurements are automated via the CodeScene tool, where we utilize the code health metric, Time-In-Development calculations, and defect summaries with file level granularity. The Time-In-Development dimension is important because from a business perspective, Time-In-Development has an obvious impact on time-to-market. And the number of defects influences both the product experience as well as the engineering productivity; a high degree of bugs leads to unplanned work, a phenomenon that Gene Kim prominently dubbed as the silent killer of IT projects.
The Code Health metric: a proxy for code quality
The code health metric used in our research is an aggregated metric based on 25+ factors scanned from the source code (check out the code health article for a deeper dive). The 25+ factors are known -- from research -- to correlate with increased maintenance efforts and a risk for defects. To give you some examples on code health factors, the metric includes Brain Methods/God Functions, Low Cohesion, Copy-Pasted code, deeply nested logic, the Bumpy Road code smell, and more.
Based on the presence and severity of the findings, each source code file is automatically categorized as:
- Green Code: healthy code that's easy to understand and low risk for maintenance issues.
- Yellow Code: problematic code where we need to be careful to prevent further decline.
- Red Code: unhealthy code with high maintenance risks.
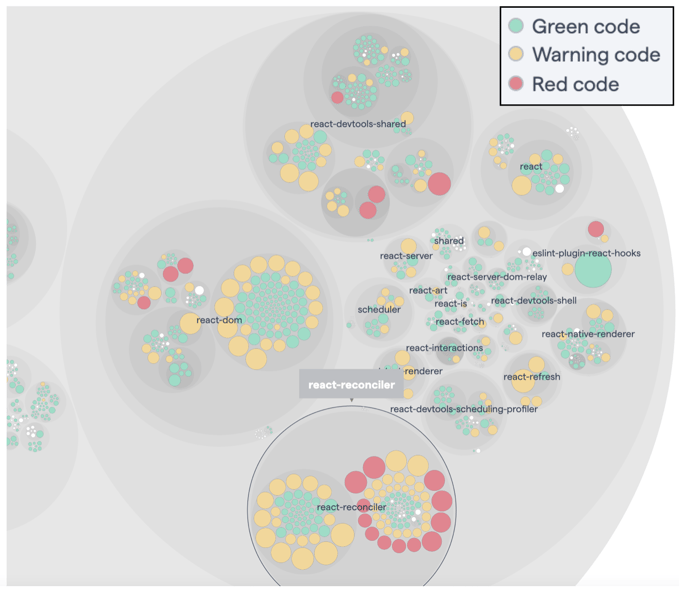
Example of a code health visualisation of React.js from Facebook: we immediately see the risky parts of the codebase (visualisation via the CodeScene tool).
With the metric covered, let's look at the results.
Twice the development speed in Green Code
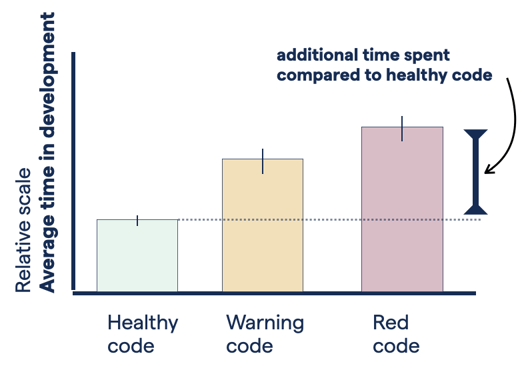
Implementing a feature or fixing a bug is twice as expensive in Red Code (relative scale).
Our first research objective investigates the link between code health and time-to-market. We do that by measuring the average Time-In-Development for Jira tasks and correlating those numbers with the code health of the impacted source code files.
Our results show that implementing a Jira task in Green Code is 124% times faster than in Red Code for tasks of similar scope. This means that a feature that takes 2 weeks to implement could have been delivered in less than one week if the code had been healthy. We also note a significant impact already at the Yellow code health level: the average development time for a Jira issue in Yellow code is 78% longer than in healthy code.
Red Code: features take an order of magnitude longer to implement
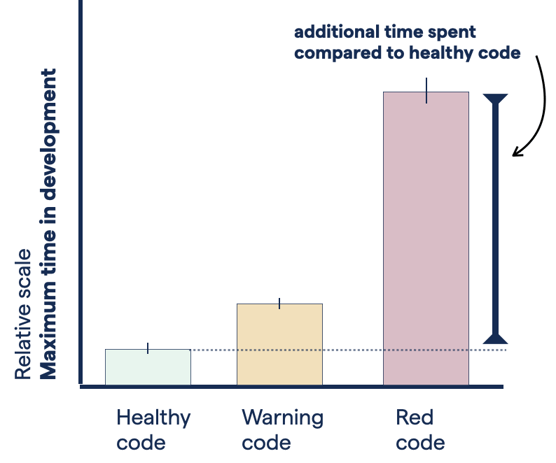
Red code: more than 9 times longer average maximum time leads to uncertainty during development (relative scale).
The additional development time for Red Code seems to match the intuition of experienced software developers: there's a significant productivity cost associated with low code quality. However, to us as a research team, the big surprise was that Red Code isn't just more expensive: it also seems to be more unpredictable than healthy code.
We explored that by measuring the maximum Time-In Development for each source code file. The results show that the maximum time to implement a Jira issue in Red Code is an order of magnitude larger than in healthy code!
Translated to a business context, an order of magnitude difference in completion time means high uncertainty. As a product person, high uncertainty makes it impossible to keep any commitments, be it to customers or internal stakeholders. And to a developer, uncertainty causes stress, over-time, and missed deadlines.
15 times more defects in Red Code
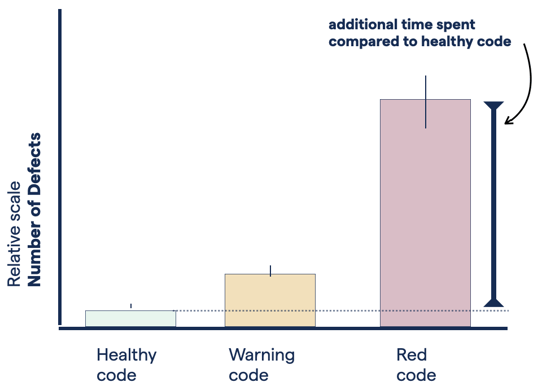
Red code: 15 times more defects compared to high-quality code (relative scale).
We also wanted to explore the external quality perspective: does Red Code contain more bugs then code of higher quality? Again, the results are quite dramatic: Red Code has, on average, 15 times more defects than healthy code!
This finding adds another business dimension, namely customer satisfaction. A high degree of defects also impacts the development team in the form of unplanned work. Bug prone code makes it hard to stay focused on planned tasks, which in turn causes additional waste via context switches.
Summary: A call to put theory into practice
Over the past decade, I have focused on exploring new techniques for managing technical debt. I've done multiple presentations on technical debt, and wrote two books on how to succeed with software at scale. I've also been fortunate to work with many organizations around the globe, and learned a lot from those interactions.
My observation during all these years is that most tech managers are aware of the consequences of technical debt. However, technical debt hasn’t been possible to quantify at the level of the source code. Therefore, the few companies that do manage technical debt spend a significant amount of the allocated time on identifying and prioritizing potential issues to fix. Actual improvements are more rare, and the outcome uncertain.
The lack of quantifiable benefits make it hard to balance the need for improvements with the constant push for new features. As such, one of the big wins with this study is that code quality improvements can now come with a business expectation.
Further, knowing the health of your code reduces risks, aligns expectations, and empowers development teams. If you know the health of your code, then you'd use that as input when planning or prioritizing features. Planning a feature that involves Red Code implies that the outcome is: a) higher risk, b) more expensive in terms of development time, and c) a large uncertainty in completion time.
As developers, we now have a way of communicating these risks to business: we can make data-driven decisions on whether to go ahead with the feature as planned or, in case of code health issues, decide to start by refactoring existing code to increase the probability of success.
Finally, it you want to test this on your own codebase, the code health measures are automated and part of the CodeScene tool. Now, what's the colour of your codebase?

.png)