Our research across C++, Java, and Python shows that agents working on unhealthy codebases consume almost 50% more tokens to complete the same tasks. That’s in addition to the increased defect risk covered in earlier research. You're not just getting worse output. You're paying significantly more for it.
Knowing that your unhealthy code burns excess tokens is useful. Having a workflow that prevents it from getting worse with every agent commit is what changes the outcome.
What the data reveals on token consumption
To benchmark token consumption, CodeScene's research team analyzed two tasks: single-prompt test case generation and agentic refactoring. The studies covered Python, Java, and C++ codebases. For each task, we measured token consumption across various Code Health levels, from severely degraded code scoring around 5.5 up to healthy code at 10.0.
The finding is consistent across all three languages: The less healthy the code, the more tokens an AI system burns when working on it.
Now, let’s look at how we measured this. As you’ll see, the outcomes are objectively worse in unhealthy code.
For test case generation, we instrumented the tokens needed for Qwen3-Coder-30b to generate unit tests from a single prompt. The dataset includes 10k C++ files, 10k Java files, and 5k Python files, all implementing comparably complex competitive programming tasks.
This is a non-trivial single-prompt task for an LLM, but it reveals interesting patterns. C++ is clearly the most difficult language in the mix. For unhealthy code, the model not only generates test suites with lower code coverage, but also needs significantly more input tokens to process code with maintainability issues.
Median line coverage
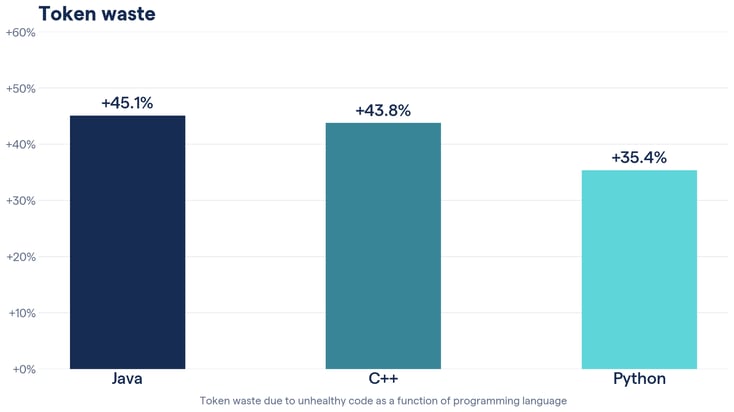
| Language | Near perfect (CH>=9.8) | Unhealthy code (CH<6) | Token waste in unhealthy code |
| C++ | 35.2% | 3.2% | +43.8% |
| Java | 77.1% | 70.4% | +45.1% |
| Python | 46.6% | 19.4% | +35.4% |
These aren't marginal differences. At current frontier model pricing, a team running agents daily against an unhealthy Java or C++ codebase may spend nearly twice as many tokens as necessary. On top of that, LLMs stumble substantially more often when completing tasks on unhealthy code. This increases the need for careful safeguards, which themselves tend to drive token-hungry iterations.

Looking more closely at the median input tokens, the pattern is consistent across the languages. As Code Health improves, the LLM needs fewer input tokens to process the code, with the clearest reductions in C++ and Java. Python shows the trend at a smaller scale, likely because of its more concise syntax. The overall conclusion holds: healthier code is simply cheaper for the model to work through. And this finding remains robust also after controlling for size (SLoC).
And the pattern of increased token spend holds for agentic refactoring. The chart below shows the percentage of increased input and output tokens when refactoring code for maintainability. The results come from refactoring with the open-source agent gptme, powered by Qwen3-Coder-30b and guided by the CodeHealth MCP server. Compared with the Near Perfect baseline, unhealthy code requires substantially more tokens for all three languages.
The effect is visible for input tokens, but it is even more pronounced for output tokens. For Java, a language known for its verbosity, the iterative refactoring process uses around 120% more output tokens when Code Health drops below 8. Even code in the 8-9 interval drives considerable token waste.

Why this happens
As the research shows, Code Health acts as a protective buffer. Healthy code reduces error-generation risk and gives AI the structural clarity it needs to act more predictably.
The token reduction is a direct consequence of that behavioral difference.
This is why the effect shows up consistently across languages, despite the different numbers. Any codebase with high cognitive complexity makes agents hallucinate and behave badly.
What this means at scale
Most enterprises are now on a trajectory towards agentic AI. The general assumption is that faster coding will translate into increased productivity across the board. But the uncomfortable reality as our benchmarks show is that the average health of industrial codebases is far from AI-ready.
Token costs compound. An enterprise running agents across multiple unhealthy codebases is consuming the budget at a scale most engineering leaders haven't yet accounted for.
A workflow to reduce token spend: Code Health aware MCP tooling
The good news is that this excess token spend can be mitigated. At CodeScene, we’ve packaged the Code Health metric into an MCP Server.
That MCP server ensures your coding agents become code-health-aware, meaning a) new code becomes automatically safeguarded, b) existing code that isn’t yet AI-friendly gets an uplift, and c) the resulting outcomes are both improved correctness and reduced token spend. That’s valuable.
Try it out for free — your token budget is going to thank you later.
With the safeguards in place, we ensure that teams only scale agentic coding with healthy enough code, which means savings on tokens in the long run.
Investing in Code Health means keeping the surface agents working on AI-friendly, which, as the data shows, is also the cheaper surface to work on.
Here are best practice patterns for agentic coding that your team can adopt.
Methodology: Analysis conducted across C++, Java, and Python codebases using the Qwen3 model in the gptme agent framework. Token consumption measured at each Code Health from 5.5 to 10.0, comparing median tokens-in and tokens-out across tasks. Results are consistent across all three languages. Full research data available on request.

.png)